Bernoulli distribution & binomial trials
by theDataTalks . 26 Apr 2020Bernoulli distribution
Bernoulli distribution contains categorical variables, and they are like qualitative attributes. It has only binary outcomes like success/failure, yes/no, like/dislike, etc.
With a Bernoulli random variable, we will have only one trial.
There is nothing in between to find a mean or something else.
Success = 1
Failure = 0
The mean is calculated using the probability-weighted sum.
µ = (probability of failure)*0 + (probability of success)*1
If the probability of success is p, then the likelihood of failure will be q = (1-p)
Mean = µ = E[X] = (1-p) * 0 + p * 1
= p
Variance = ν = σ² = E[(X-µ)²] = Σ(x-µ)²*p(x)
= (1-p)(0-p)² + p (1-p)²
= p² - p³ + p - 2p² + p³
= p(1-P) = pq
Standard deviation = σ = √(p(1-p)) = √(pq)
When the event is iid (identical independent distribution), then.
(iid: all samples are mutually independent & all samples will have the same probability distribution)
Variance of sample mean = ν’ = σ²/n
(Please read this article for details standard Error)
Standard error = Standard deviation of statistics
= SE = √ν’ = σ/√n
If the event is fair, then.
p = ½
σ = √(½ * ½) = ½
SE = 1/(2√n)
Example:
SE for a 15 coin flips, If each event is fair & iid
SE = 1/(2√15) = 0.1291 = 12.91%
A set of R commands will return the above value.
Generate 1000 rows of trials with each row contain 1500 individual trials
trials <- matrix(sample(0:1, 15000, TRUE), 1000)
Find means of each row
meanofrows <- apply(trials, 1, mean)
Find standard deviation of means
sd(meanofrows) = 0.1266 = 12.66% (This is approximately equal to 12.91%)
Binomial trials
Binomial trials are generated from iid Bernoulli trials.
Let X1, X2, X3 … Xn are iid bernoulli trials then
Example:
We can calculate the probability of getting at least seven girls(none are twins) out of 8 children for a parent as
A simple R command will give the above value.
= choose(8,7) * 0.5^7 * (1-0.5)^(8-7) + choose(8,8) * 0.5^8 * (1-0.5)^(8-8)
=0.03516
(OR)
= pbinom(q=6, size=8, prob=0.5, lower.tail=FALSE)
= 0.03516
Here q = 6 means > 6 values, which are 7 & 8.
Binomial trials & p-value
Please read this page p-value before starting this section.
Consider a coin flip of 100 times.
We get 2100 possible combinations.
If we would like to get 50 heads out of 100 coin flips, i.e., the probability of getting 50 heads {P(X=50)} can be calculated as below.
Out of possible out comes only of them will have exactly 50 heads. Here can be read as 100 choose 50 i.e., =
So the probability to get 50 Heads is ÷ = 0.0796 = 7.96%
A simple R function will return the above value.
Density function
dbinom(50, 100, prob = 0.5)
= 0.07958924 = 7.96%
When P(X=50) = 0.0796 then the p-value will be P(X≤49 OR X≥51), which is 1-0.0796 = 0.9204
P(X≥51) can be found using the below formula.
i.e., (consider the coin is not biased)
+… +
= 0.4602 = 46.02%
A simple R function will return the above value.
Cumulative distribution function
pbinom(50, 100, 0.5, lower.tail = FALSE)
= 0.4602054 = 46.02%
Similarly, p-values for other possible observations are given below.
| 100 coin flips E(X) = 50) |
|---|
| P(X ≤ 49 or X ≥ 51) = 0.9204 |
| P(X ≤ 48 or X ≥ 52) = 0.7644 |
| . . . . . . . . |
| P(X ≤ 41 or X ≥ 59) = 0.0886 |
| P(X ≤ 40 or X ≥ 60) = 0.0569 |
| P(X ≤ 39 or X ≥ 61) = 0.0352 |
| P(X ≤ 38 or X ≥ 62) = 0.0210 |
| P(X ≤ 37 or X ≥ 63) = 0.0120 |
| P(X ≤ 36 or X ≥ 64) = 0.0066 |
| . . . . . . . . |
| P(X = 0 or X = 100) = 0.0000 |
When we plot the above values, we get the below bell curve.
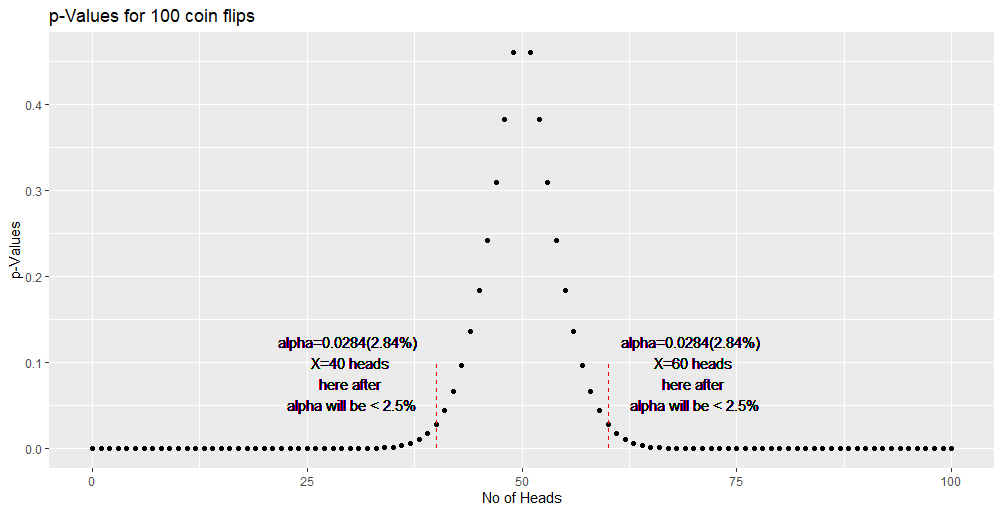
For the above binomial distribution,
- Null hypothesis H0 = 50 heads
- At 5% significance level (α) we get 95% confidence (1-α)
- We reject H0, when we get <40 heads (2.5%) or >60 heads (2.5%).
- i.e., 95% of the time we correctly conclude that the coin is indeed fair
- i.e., 95% of the time we correctly accept H0
- i.e., 5% of the time we erroneously conclude that the coin is unfair.
- i.e., 5% of the time we erroneously reject H0. This leads to Type-I error. (Fail to accept H0 when it is true)